redis增量订阅工具redis-canal分享
项目背景
该项目需求来源于点我达骑手实时压力系统,为了了解业务区块历史各个时点的压力状况,我们需要将历史数据持久化下来。
起初方案:数据双写
点我达压力系统基于spark,实时计算自然区域网格压力值并持久化到redis存储中,在写完redis后会再往hdfs上再写一份,用来保存历史数据。
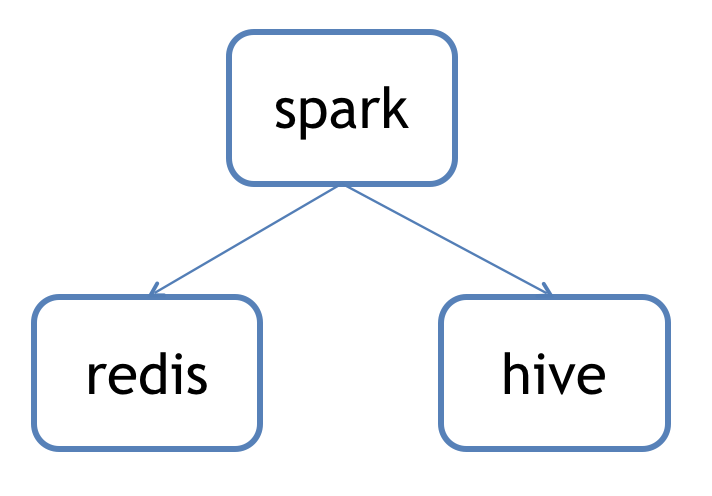
改进的方案:数据订阅 尝试通过redis的数据同步机制,实时获取增量数据,并同步到hive alt
项目介绍
- 名称:redis-canal
- 释义:canal的redis版本
- 语言:java
- 定位:基于redis数据库的aof的增量日志,提供数据的订阅和消费
- 依赖:kafka,jstorm(非必要)
- 源码:https://github.com/bigdataATdianwoba/redis-canal
工作原理
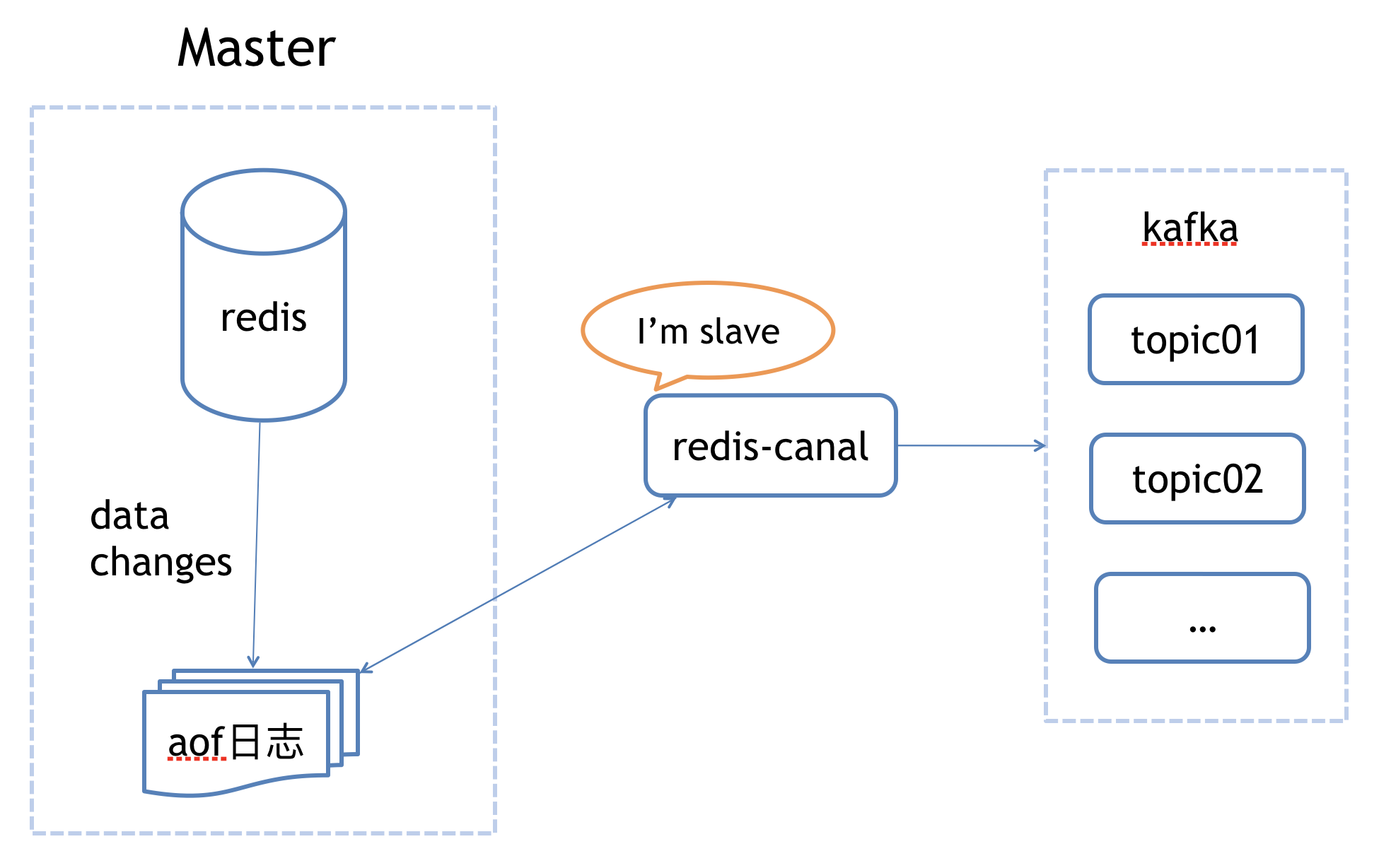
alt redis-canal会将自己伪装成redis的slave,来进行数据同步请求,master接收到开始同步的命令后则会将data changes生成的aof日志信息实时通过socket方式传输给redis-canal,redis-canal这边接收到change后,进行aof文件解析,进行数据封装,写入到我们大数据的kafka集群,已供后续应用消费使用
AOF数据格式
比如一条redis命令:“set name silas” 转换成aof格式如下:
$3 # 第一个参数长度为 4
SET # 第一个参数
$4 # 第二参数长度为 4
name # 第二个参数
$4 # 第三个参数长度为 4
Jhon # 第二参数长度为 4
伪装slave过程

使用redis的info命令查看master信息

架构设计
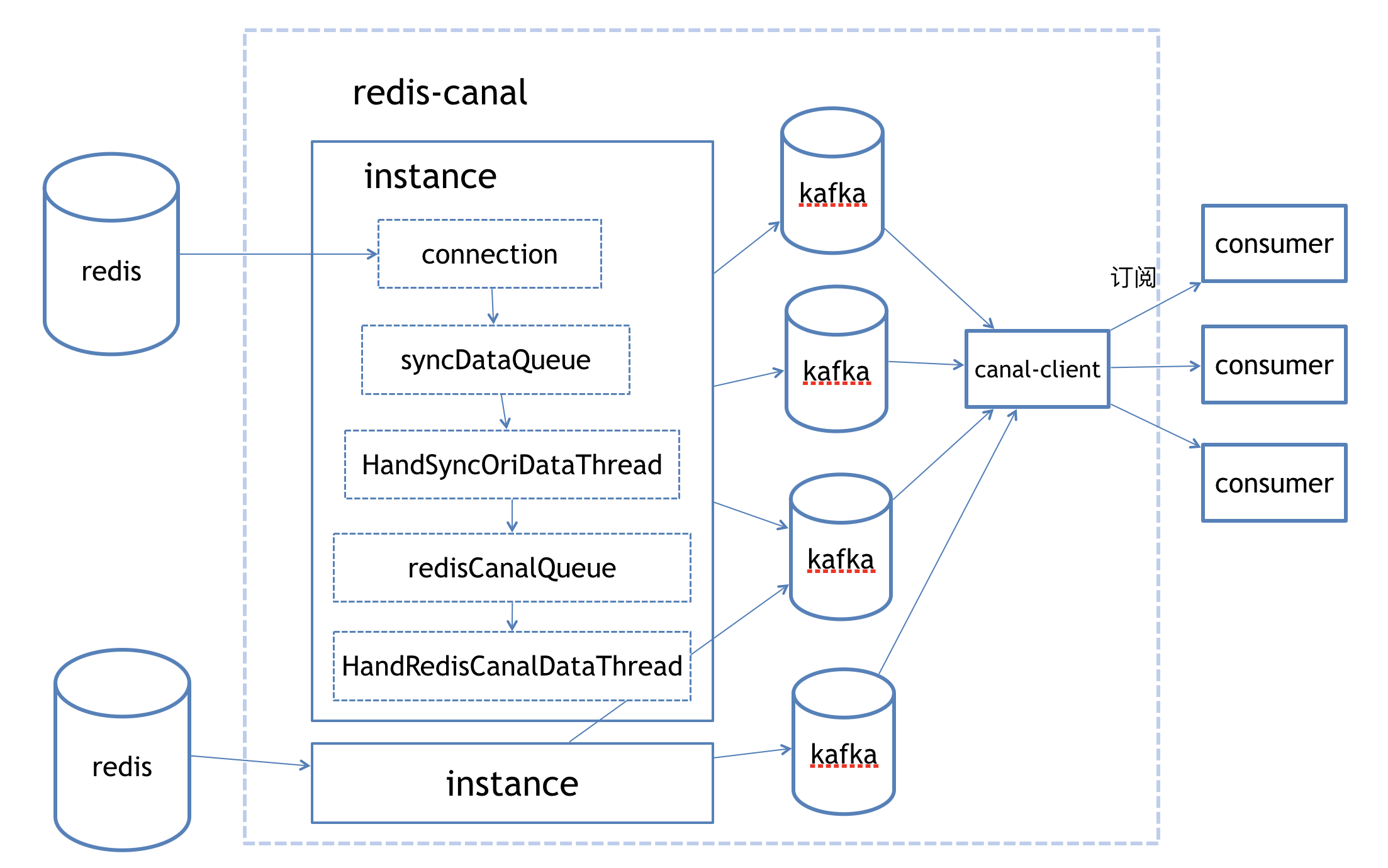
源码详见github https://github.com/bigdataATdianwoba/redis-canal
运行
启动方式:
- 普通jar包启动方式
java -jar redis-canal-server.jar --name RedisCanal \
--host localhost \
--port 6379 \
--password xxx \
--broker localhost:9092 \
--topic redis.canal.data
- jstorm启动方式
jstorm jar redis-canal-server.jar com.dianwoba.bigdata.redis.canal.bootstrap.jstorm.CanalTopo \
--name RedisCanal \
--host localhost \ --port 6379 \
--password xxx \
--broker localhost:9092 \
--topic redis.canal.data
redis-canal启动时打印出来的aof日志信息
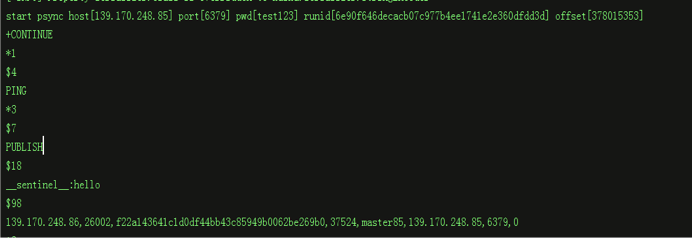
redis-canal默认从master最近给slave同步的offset开始同步,则接收到的第一条aof日志为“+CONTINUE”,该模式下,master不会在建立同步连接后将全量的rdb文件传输给slave,这样避免了长时间的等待,且全量同步一次rdb文件对master的性能是有消耗的。
一般来说生产环境redis架构大多为1主1备,redis-canal可以选择对主或者对从进行同步。唯一区别的地方在于,如果是对备库进行同步,备库自己是没有其他slave来同步自己的数据的,则备实例就不会有 master_repl_offset 标记,那么redis-canal开始进行订阅则必然会进行一次rdb全量数据传输,且备库在传输前会进行一次bgsave,这个对性能影响较大;如果是对master进行同步,则是增量同步,影响较小。
注意点:
-
redis实例每次接受到同步请求命令,不管是sync还是psync,都会触发一次自身的bgsave,这个目前避免不了 。
-
实际生产上备库并没有业务应用的读写请求,对备库来说一次bgsave也不算啥,要是数据比较多的比如几十个G这种情况,那影响时间就有点较长了,开启同步建议在非业务高峰。
标签云
-
CactiLUA集群AnsibleRsyncCurlZabbixRedhatIptablesCentosShellVirtualminAndroidSnmpSVNIOSVirtualbox容器WiresharkSwarmJenkinsVagrantKubernetesSambaGolangLVM监控PHPInnoDBGITMySQLSystemdNFSHAproxySwiftPythonsquidDNS备份GoogleOfficeNginxRedisDeepinDockerLinuxWindowsVsftpdCrontabKloxoWordPressTensorFlowTcpdumpSecureCRTAppleOpenStackYumTomcatOpenrestyLighttpdDebian部署MemcacheFirewalldSaltStack代理服务器缓存PostgreSQLSSHApacheMacOSVPSSQLAlchemyMongodbiPhoneFlaskWgetMariaDBOpenVZKVMSupervisorCDNFlutterPuttyUbuntuPostfixSocketBashWPSKotlin